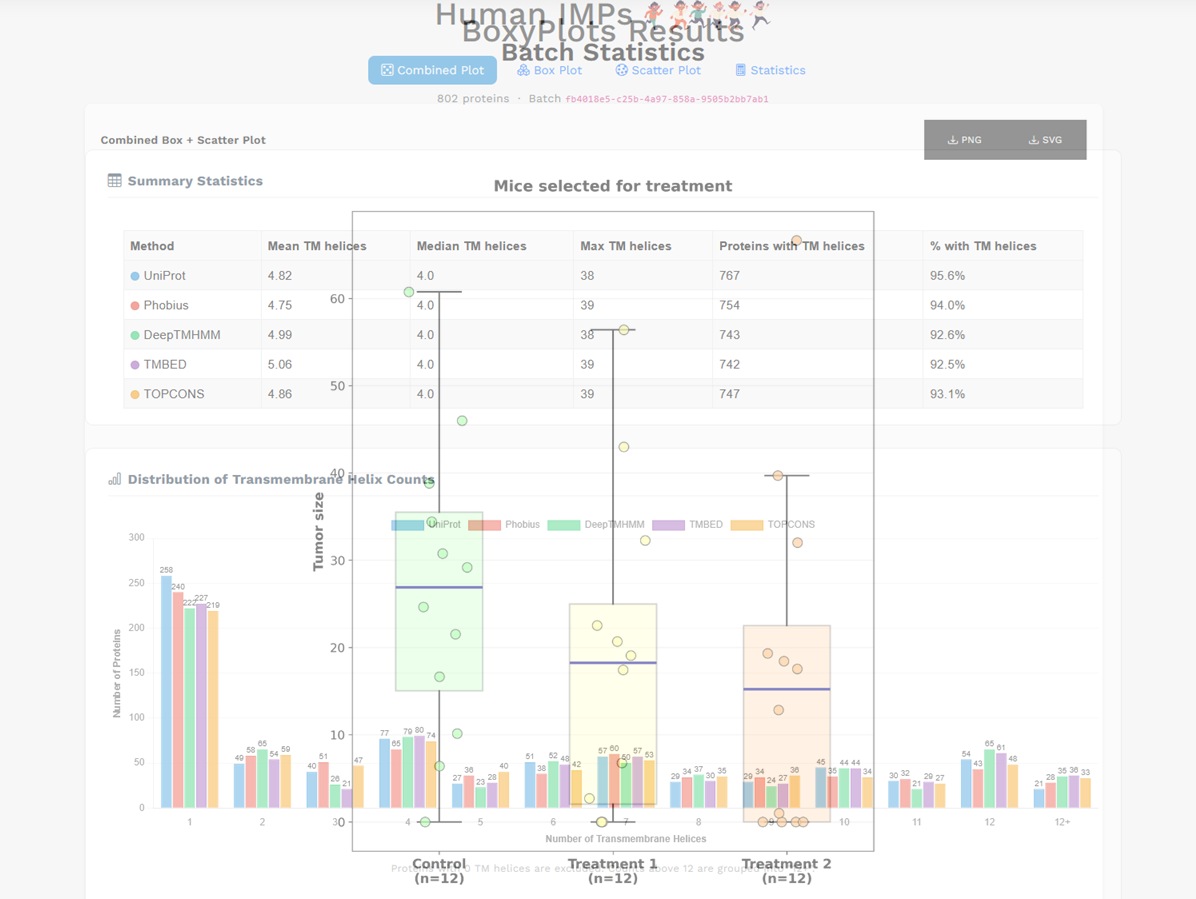
Zas nějaké přidané funkce do Human IMPs, a jako třešnička na dortu: krabice
Naposledy jsem Human IMPs vylepšoval tím, že jsem k nim poté co získaly grafický output přidal další dva predikční algoritmy a jejich data uložil do PostgreSQL databáze (předtím tool četl data z csv souborů, což bylo velmi provizorní, pomalé a určitě ne profesionální). Když jsem pak Human IMPs prezentoval na konferenci CzechMS, nějaký zájem už to vzbudilo, ale potýkal jsem se také s problémem, jak aplikaci prezentovat na posteru, a jak naplnit potřebu splnit tematické zadání grantového projektu, z nějž byly placeny moje jízdenky a hotel.
Výsledkem byla sada statistických výstupů, část takových, které jsem byl zvyklý prezentovat u dat souvisejících s membránovými proteiny dříve, část takových, které popisují míru shody či neshody mezi jednotlivými pěti predikcemi. Nová funkce Human IMPs vychází přesně z nich: u batch analýzy přibylo tlačítko “Generate Statistics”, které vám několik statistik ukáže. Jmenovitě to jsou
1) statictický souhrn (základní statistiky, včetně výpočtu pokrytí celkového membránového proteomu vzorkem):
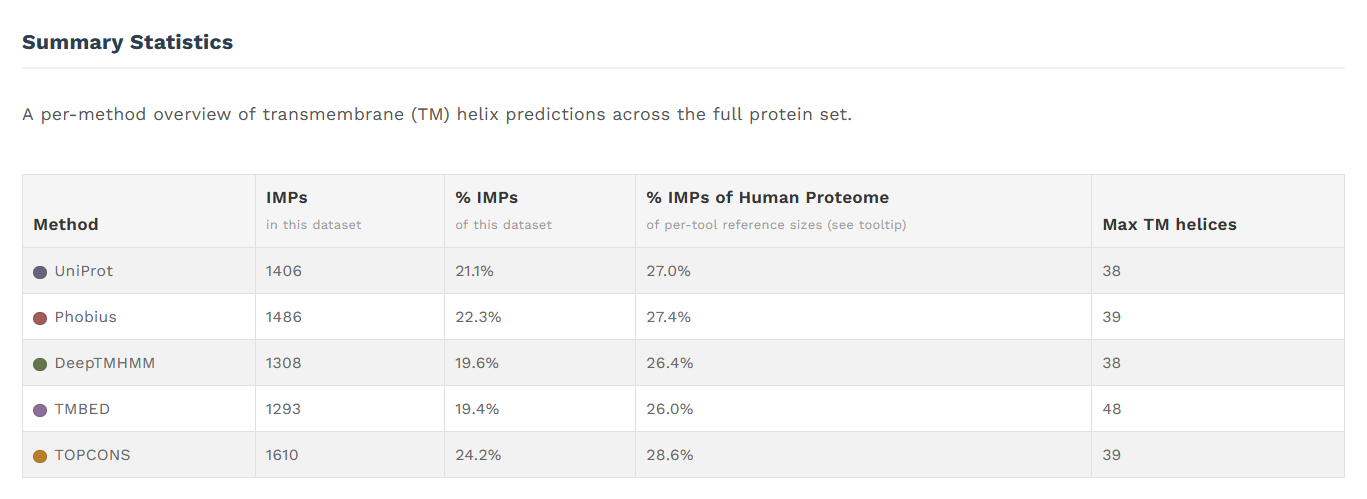
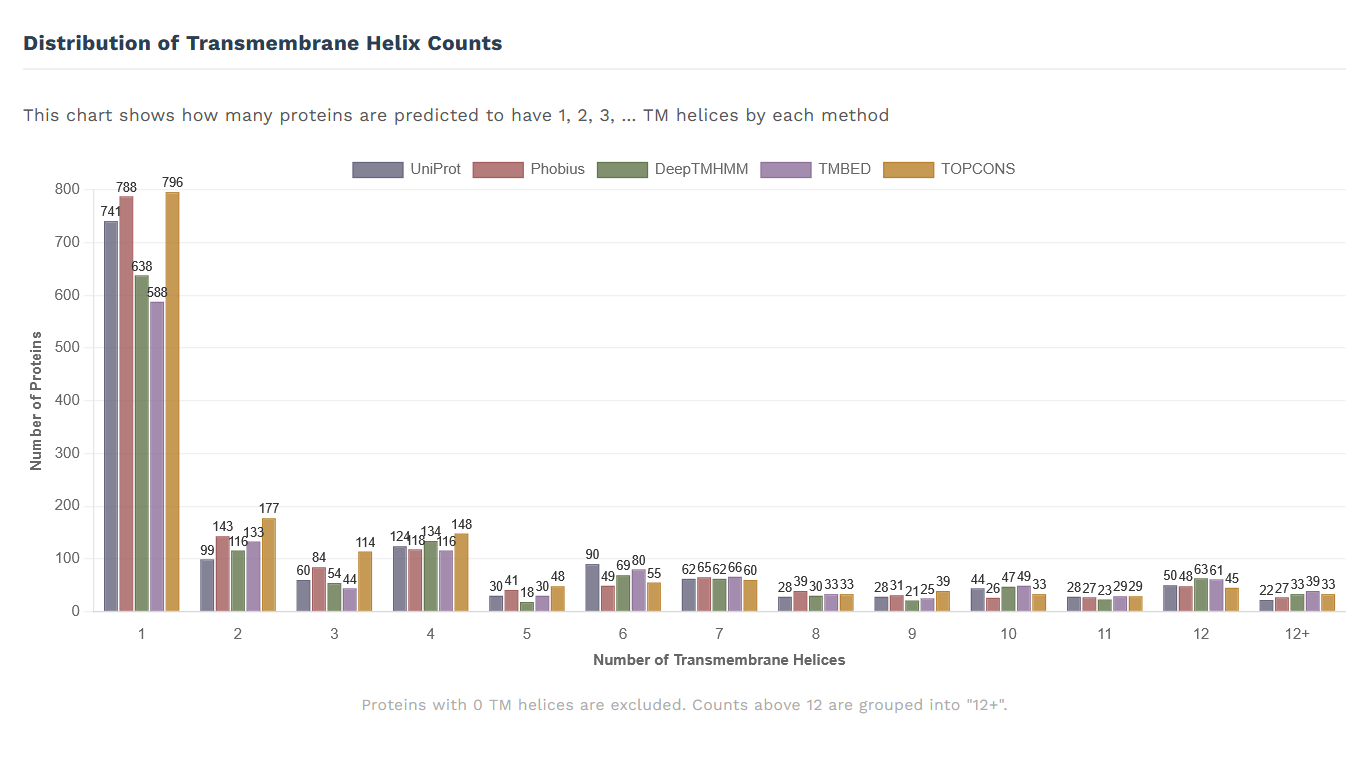
Distribution of Transmembrane Helix Counts (počty proteinů s určitým počtem transmembránových alfa helixů, počínaje 1 a konče 12+),
srovnání zastoupení IMPs s různým počtem transmembránových helixů s celkovým membránovým proteomem:
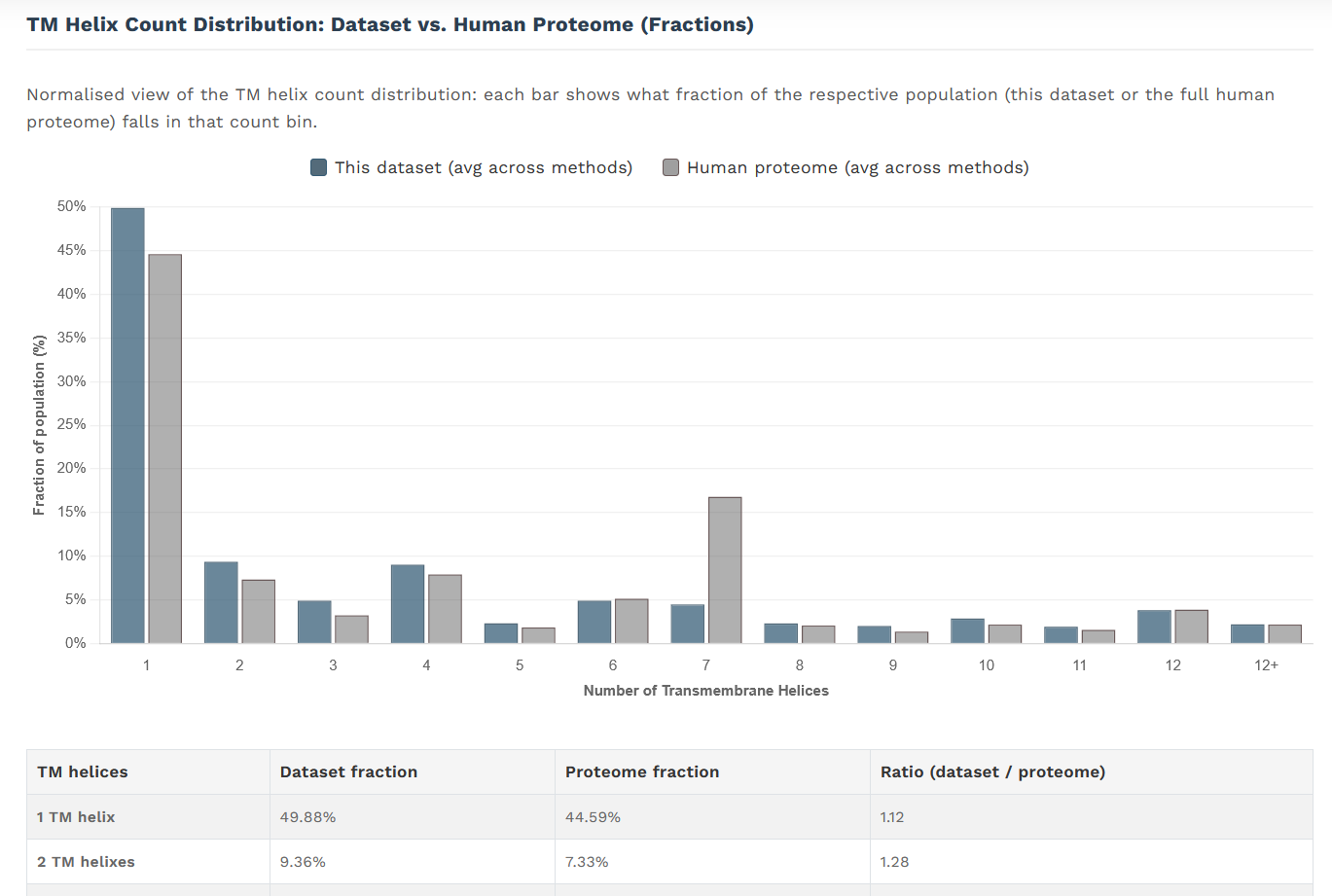
srovnání zastoupení IMPs s různým počtem transmembránových helixů s celkovým membránovým proteomem (absolutní počty):
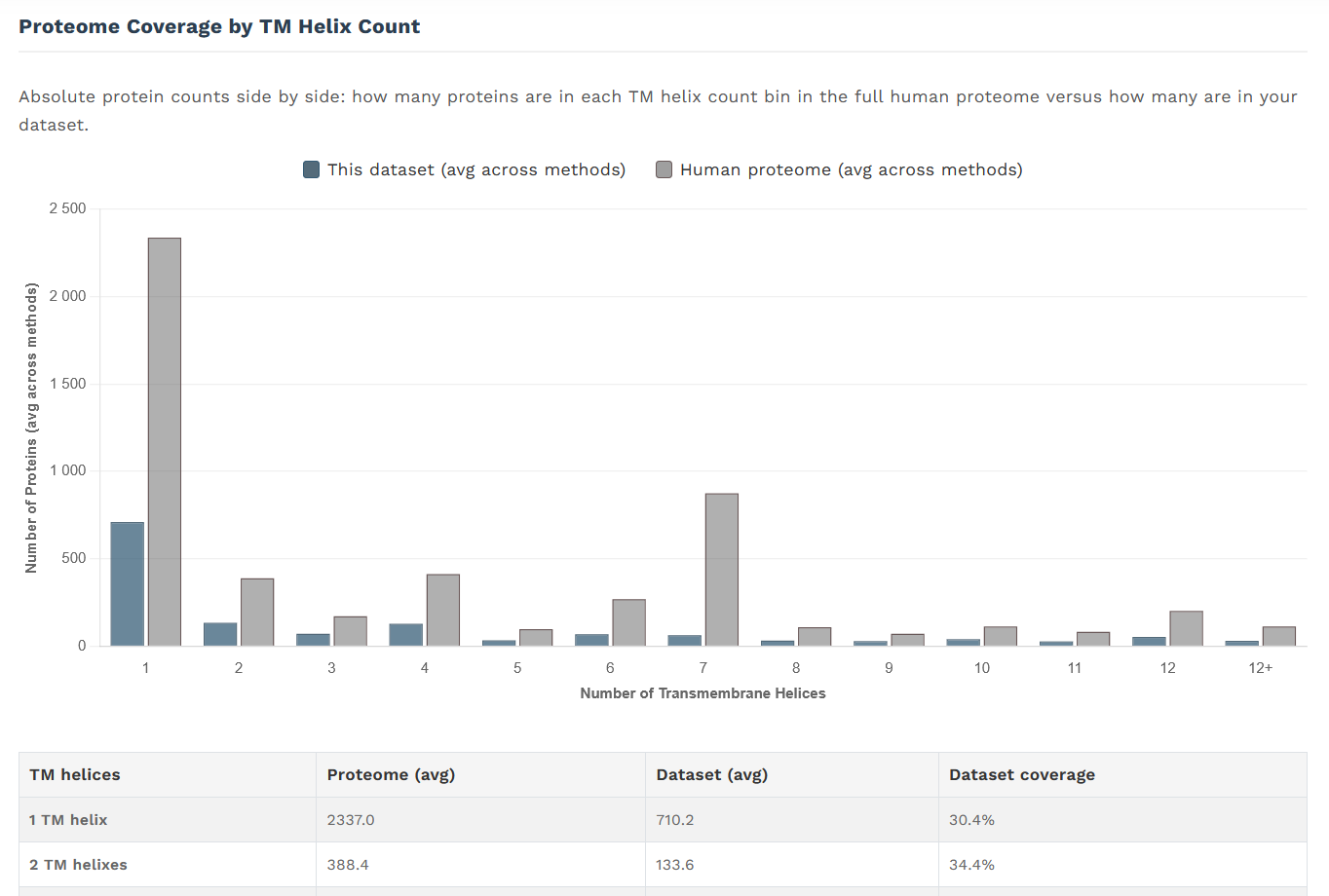
srovnání zastoupení IMPs s různým podílem transmembránové sekvence s celkovým membránovým proteomem (absolutní počty):
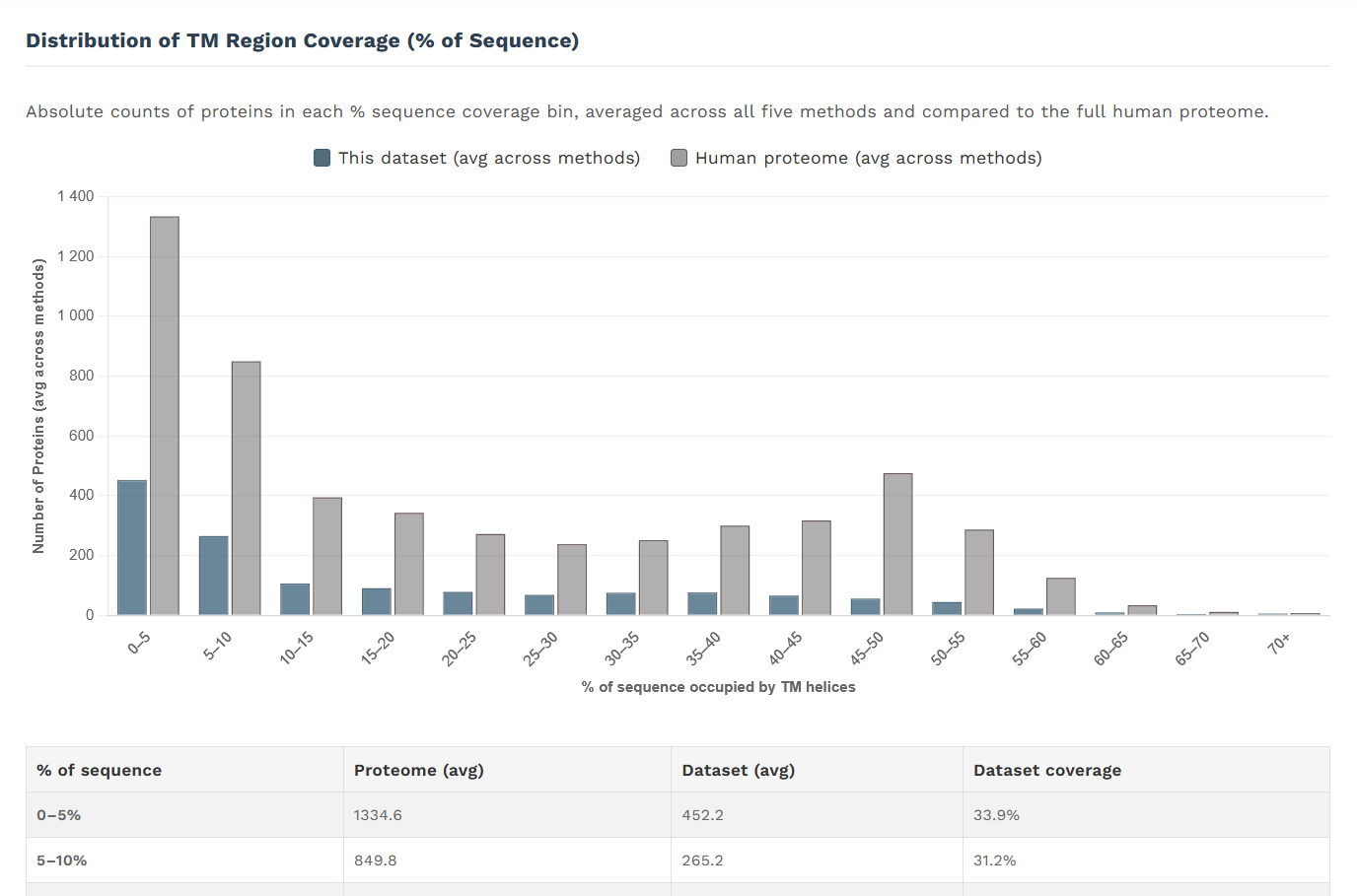
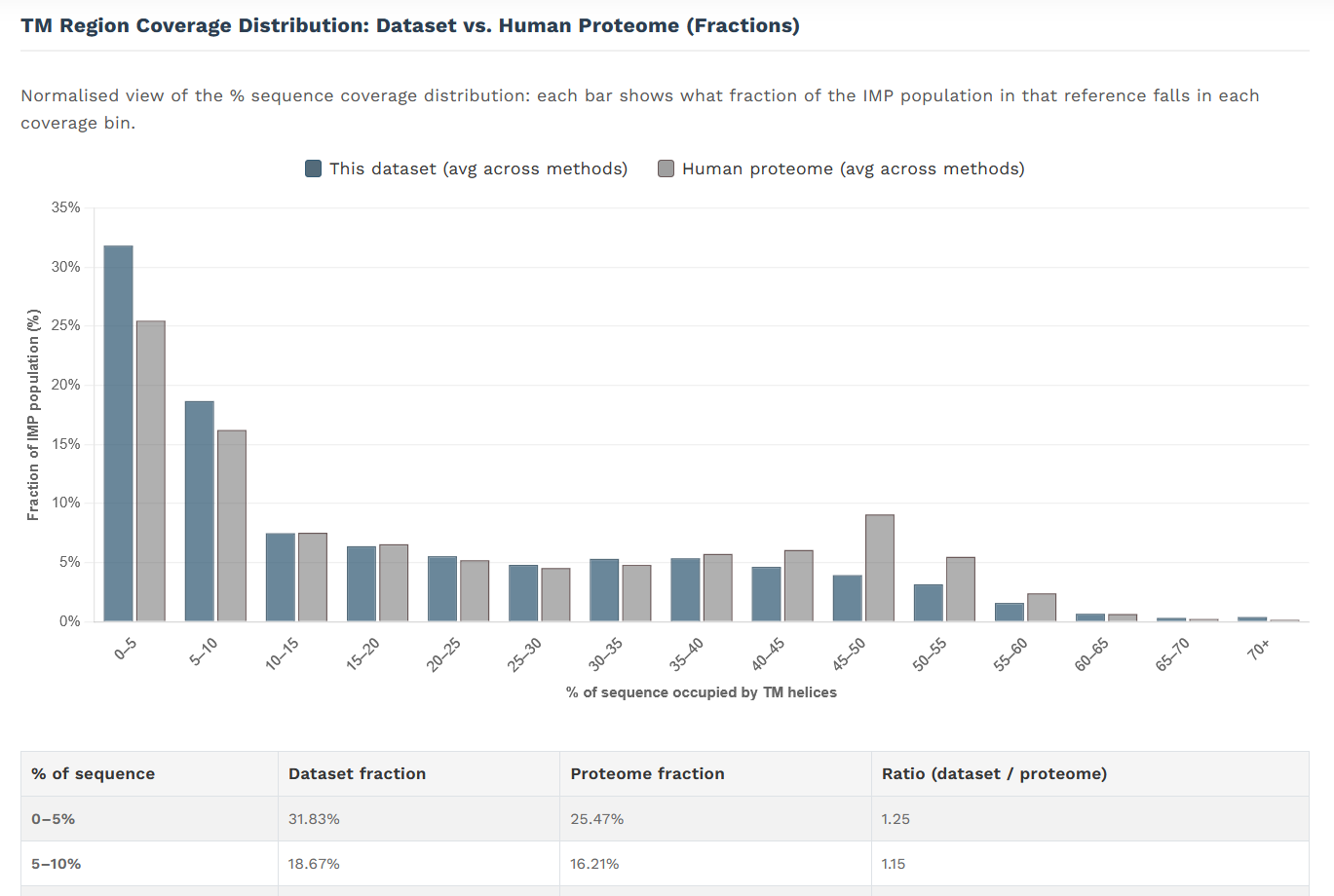
srovnání zastoupení IMPs s různým podílem transmembránové sekvence s celkovým membránovým proteomem:
rozdělení integrálních membránových proteinů v batchi podle toho, zda se u nich všechny algoritmy shodují, že jsou membránové, nebo se shodují 4, 3, 2, či jen jeden
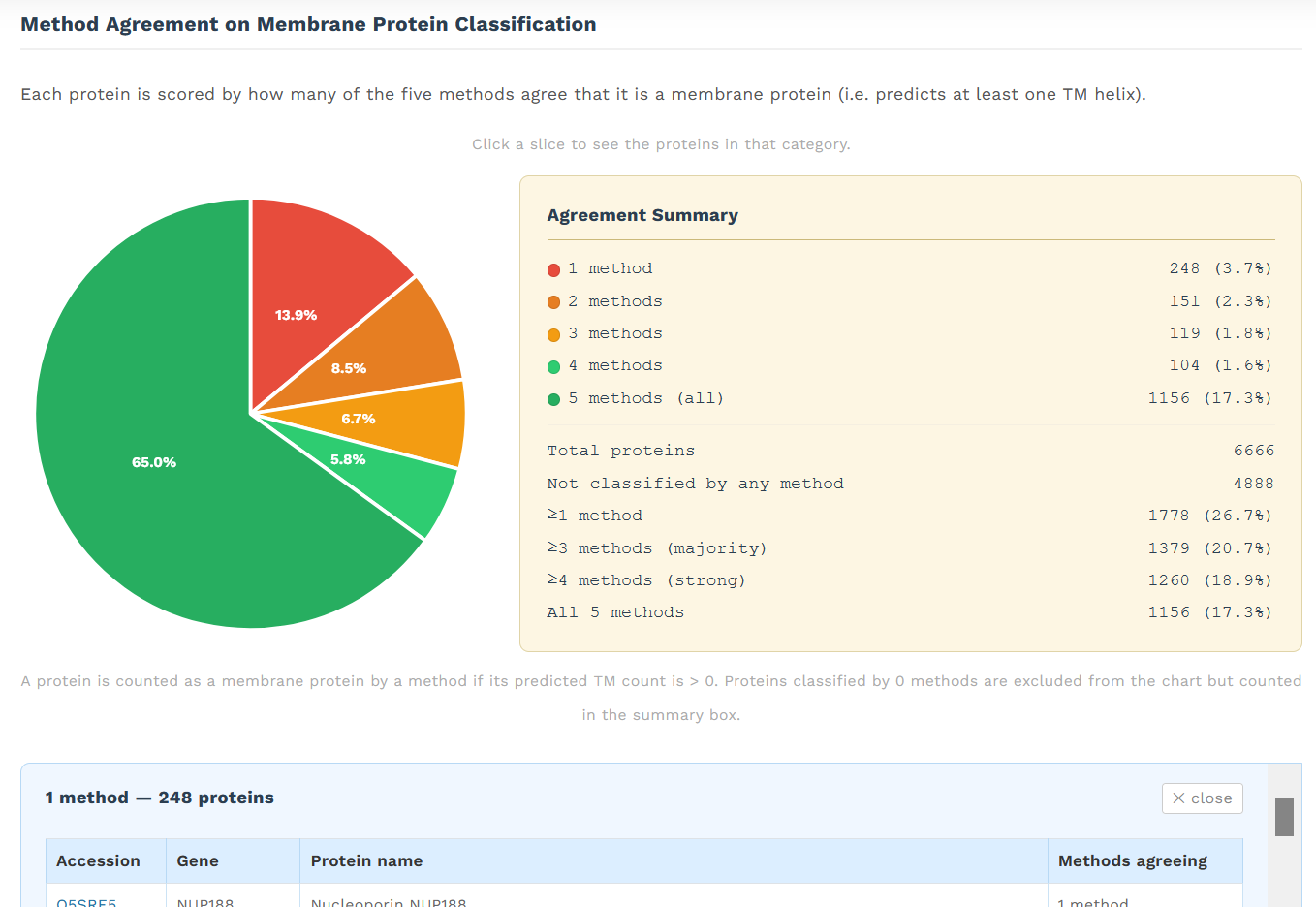
zda se na počtu predikovaných transmembránových alfa helixů shodují všechny algoritmy, nebo jen 4, 3, 2 či žádný:
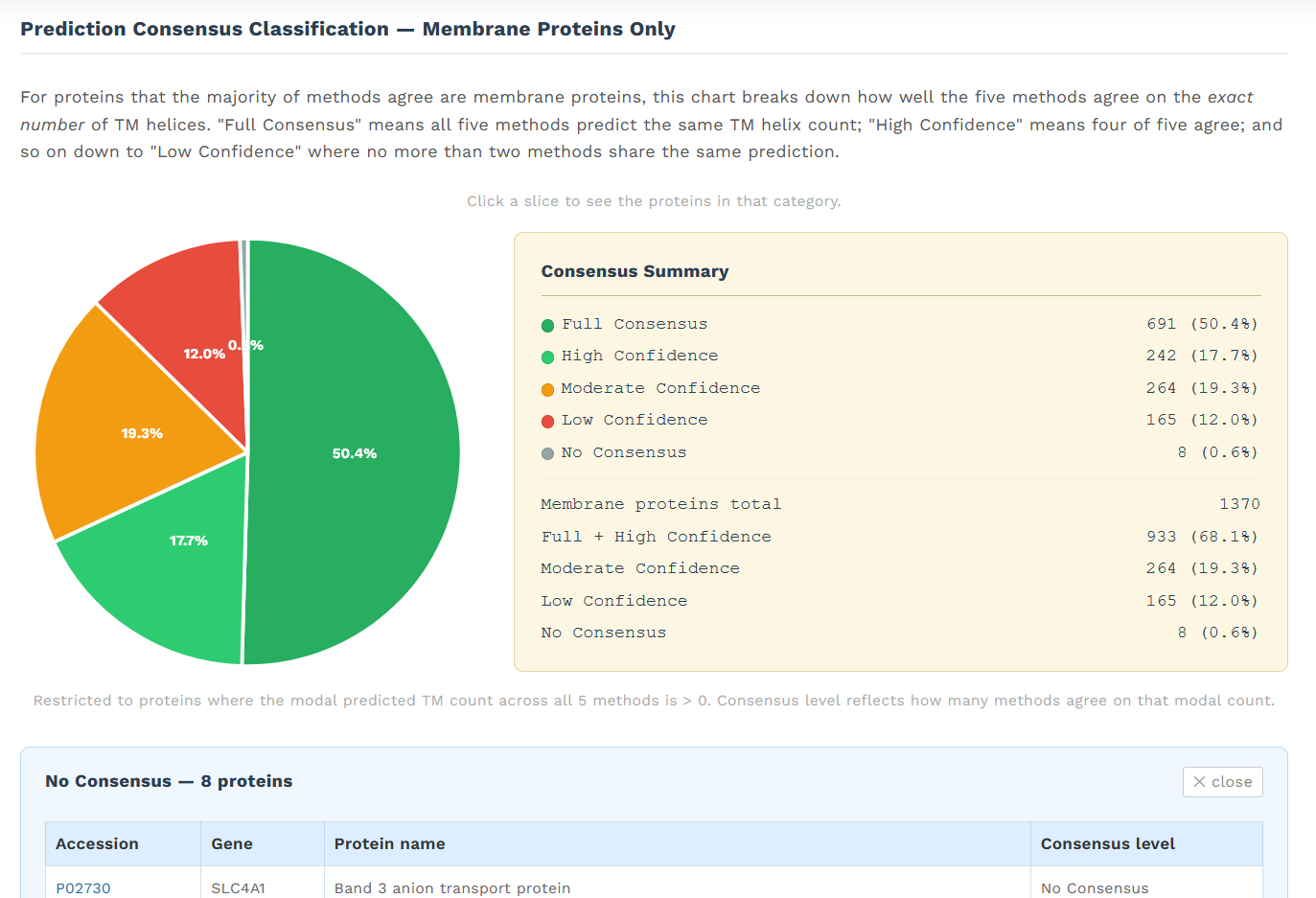
Zároveň je možné u posledních dvou grafů rozkliknout jednotlivé kategorie a zpětně dohledat. Například kuriózní neshoda ani jednoho algoritmu na počtu transmembránových helixů může znamenat toto: 10, 11, 12, 13 nebo 14?

To jsou statistiky po drobném usměrnění. Je ještě potřeba dodat jednu dodělávku v batch results - ty nyní kromě počtu a výčtu transmembránových alfa helixů ukazují i právě procentní podíl sekvence tvořené transmembránovými alfa helixy. To je metrika, která ukazuje “membránovost” daného proteinu z trochu jiného pohledu, než je pouhý počet transmembránových alfa helixů. Dva proteiny s dvanácti transmembránovými alfa helixy mohou mít 50 a 150 kDa a míra jejich “membránovosti” se pak poměrně liší.
Pokud chcete vidět výsledek ale nemáte zrovna po ruce sadu membránových proteinů, na vyzkoušení můžu poskytnout třeba tyhle:
Q9Y227 Q9Y241 Q9Y271 Q9Y282 Q9Y287 Q9Y289 Q9Y2D2 Q9Y2E8 Q9Y2G3 Q9Y2Q0 Q9Y2U8 Q9Y320 Q9Y385 Q9Y3A6 Q9Y3D6 Q9Y3E0 Q9Y3P8 Q9Y3Q3 Q9Y487 Q9Y4L1 Q9Y4P3 Q9Y4W6 Q9Y519 Q9Y548 Q9Y584 Q9Y5Q0 Q9Y5S1 Q9Y5U9 Q9Y5Y0 Q9Y639 Q9Y666 Q9Y672 Q9Y673 Q9Y6A9 Q9Y6G1 Q9Y6K0 Q9Y6M5 Q9Y6M7 Q9Y6N1 Q9Y6R1 Q9Y6X5
Druhá, nově zveřejněná webová aplikace je jen taková drobnůstka, BoxyPlots. V Excelu jdou boxploty nějak udělat, ačkoli to tedy rozhodně je hodně daleko od intuitivního postupu. Měl jsem tedy svoje boxplotí kódy pro vytváření výstupů z ELISA a měření myších nádorů v Pythonu a pouštěl si je v Google Colab, ale i to mi po čase začalo připadat nepohodlné, tak jsem se to rozhodl převést do podoby webové aplikace. Běží ve svaté trojici Pandas-NumPy-Matplotlib a do webu je integrovaná přes Blueprint. Myslím že je dost intuitivní na používání, vyzkoušejte sami.
To že sem umisťuji další webovou aplikaci vyvolává další potřebu: současný název domény má sice jakýsi svůj tajný smysl (nebo spíš nesmysl), ale určitou nevýhodu, že je zcela nezapamatovatelný. Proto už delší dobu zkouším vymyslet nějakou smysluplnější doménu, a zítra asi něco koupím.